Wer ist schneller beim Zahlen eintippen über den Nummerntastenfeld?
Zwei Tastaturen. Ein Programm zeigt Zufallsziffern an. Wer die Zahl als erstes richtig eingetippt hat, bekommt ein Punkt. Und das Eingabefeld wird bei beiden Spielen gelöscht. Wird ein Fehler bei der Eingabe gemacht, bekommt der Spieler einen Minuspunkt und der andere Spieler hat die Möglichkeit aufzuholen. Return muss keiner drücken. Die nächste Zahl kommt, sobald sie einmal richtig eingetippt wurde.
Ist wie Tetris, nur dass man keine Blöcke richtig positionieren muss, sondern Zahlen richtig eintippen. Strange...
21.03.2017
numpad game
Comments Off on numpad game
19.03.2017
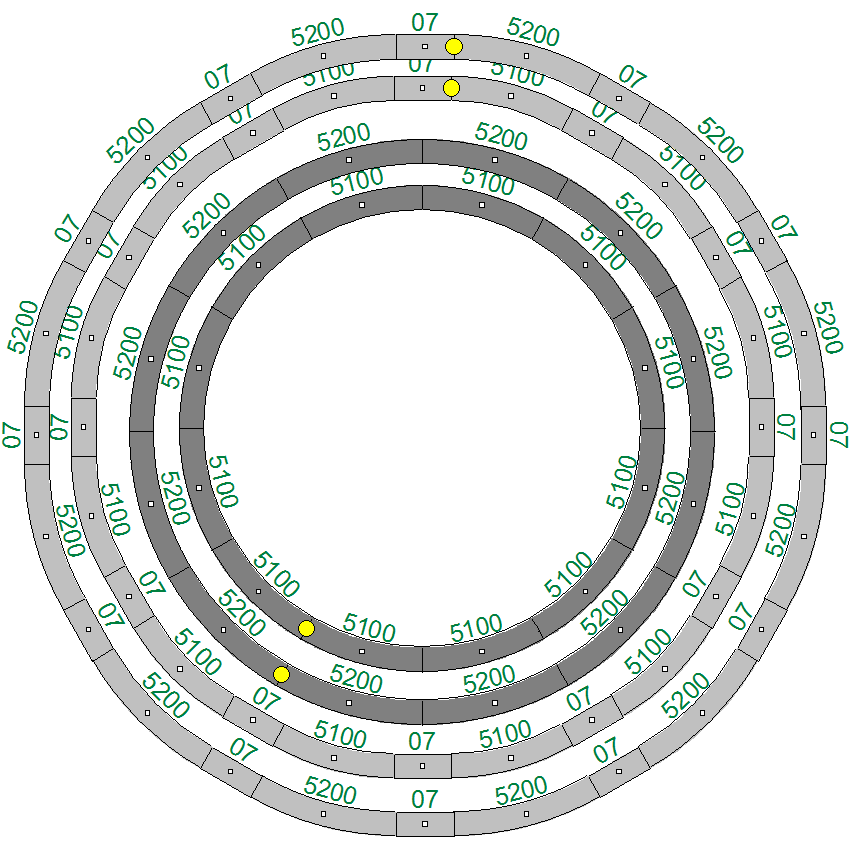
Gleiswendel - Theoretische Gedanken
Wie könnte man einen Gleiswendel mit Märklin Metallgleise bauen? Als erstes Problem fällt mir da die benötigte Steigung ein. Es soll natürlich schnell an Höhe gewonnen werden. Aber die Steigung darf nicht zu stak sein, sonst schafft es die Lok noch, oder die Waggons entgleisen.
In vielen Büchern lese ich etwas von einer maximalen Steigung von 5% auf gerade Strecke. Nun hat ein Wendelkreis keine geraden Strecken. In Kurven wird immer mal eine maximale Steigung von 3% angegeben. Ehr weniger. Da der Gleiswendel eine einzige Kurve ist, würd ich zu 2% tendieren.
Nur haben die Metallgleise einen fixen Kreisradius, und können nicht wie die Kunststoffgleise in beliebig weiten Kreisen verlegt werden.
Wie viel Prozent Steigung ergibt sich für den Normalradius bei minimaler Durchfahrtshöhe für Oberleitungsbetrieb?
Es gibt Normalkreis 5100 mit 36cm Radius. Den Parallelkreis 5200 mit 43.7cm Radius. Und den Industiekreis mit 5120 mit nur 28.6cm Radius. Aber das Industriegleis ist nicht geeignet. Es lassen sich nur kleine Loks und Waggons darüber fahren. Alle anderen entgleisen. Es wurde von 1953 bis 1957 auch der Großkreis I und II mit einem Radius von 53.5cm und 58.5cm gefertigt. Aber die Gleise konnten sich wohl wegen dem Platzbedarf und Preis nicht halten. Ich bezweifle auch, dass diese Gleise sich heute in einem guten Zustand heute noch aufzutreiben sind. Also bleibt nur der Normal- und Parallelgleis.
Als Durchfahrtshöhe nehme ich 9cm an. Auch hier gibt es stark unterschiedlich schwankende Angaben. Je nach Lok, Gleise und lichter Raum der für die Hand Gottes frei bleiben muss, um die entgleisten Züge wieder einzusetzen. Und das passiert öfter als einem lieb ist...
Eine Steigung von 2% bedeutet 2cm Höhenunterschied auf 100cm Länge. Für 9cm braucht es also 450cm. Das ist schon ganz schön viel. Ein Normalkreis mit 36cm Radius hat einem Umfang von 226.2cm. Also viel zu wenig. Ein Normalkreis Kreis müsste eine Steigung von ca. 4% haben.
Versuchen wir es mit dem Parallelgleis. Durch den größeren Radius ergibt sich auch ein größerer Umfang von 274.6cm Das ist nicht wirklich mehr und entspricht einer Steigung von 3.3%.
Wir müssen den Gleisradius irgendwie größer bekommen, aber gleichzeitig nur die vorhandenen Gleise nutzen. Abwechselnd ein gerades Gleis und ein gekrümmtes könnte funktionieren. Hier ist der Einsatz moderner Software gefragt ;)
Mit Wintrack habe ich zwei weitere Radien gebaut. Einen mit 52cm und einen mit 59cm. Das entspricht einer Steigung von 2.8% bzw. 2.4%. Ich denke, größere Radien machen keinen Sinn mehr. Der Aufbau wird ja schon 1.5m im Durchmesser. Ein Nachteil ist, dass der Zug dann immer ein Stückchen gerade aus fährt, dann wieder ein Stück Kurve, dann wieder gerade aus. Das wackelt dann so.
Die Gleise müssen aber 1a Top in Ordnung sein. Über jeder Verbindung muss der Zug sauber drüber fahren.
Comments Off on Gleiswendel - Theoretische Gedanken
16.03.2017
C++ Guns - std Input/output library
Erstmal ein Link zum Thema. Die sind selten. Copy, load, redirect and tee using C++ streambufs
Und noch einen A beginner's guide to writing a custom stream buffer (std::streambuf)
Also ich muss ganz ehrlich sagen, diese C++ iostream library ist einfach nur scheiße.
Total.... unmöglich damit was gescheites zu machen. Ich meine jetzt nicht std::cout oder die ">>" "<<" Stream Syntax. Nein, man muss das Geschichtlich sehen. Die I/O Library wurde designt, also C++ designt wurde. Ist also neben std::vector und std::string eines der ältesten Sachen in der Sprache. Anders als std::vector und std::string sind diese std::*stream Klassen einfach zu abstrakt geworden.
Aber man muss das verstehen. Damals waren virtuelle Klassen und Templates neu, und wann es zuviel des Guten ist, muss man ja auch erst noch herausfinden. So finden sich in der Dokumentation gleich 11 Klassen um Zeug aus/in Datein/String/Streams zu lesen/schreiben. Ich ziehe hier absichtlich den Vergleich zu Qt und Fortran. Ja, Spass muss sein.
Bei Qt gibt es QIODevice als Basisklasse für unter anderem QFile und QBuffer und dazu QTextstream. Wobei QBuffer/Textstream hier ein normalen String meint, so wie es std::basic_stringstream ist. Unter Fortran gäbe es write/read(fhdl/string)...
Jetzt gibt es zwischen std und Qt ganz klare Unterschiede im Design. Fangen wir mit Qt an. Das ist am pragmatischsten.
* Ich will von einer Datei lesen/schreiben, nehm ich QFile.
* Ich will von einem String lesen/schreiben, nehm ich QBuffer/QTextstream.
* Ich will diese tollen Stream "<<" ">>" Operatoren, nehm ich QTextstream.
Und jetzt kommt der clou:
Egal ob man mit Dateien oder Strings arbeitet, die Stream Operatoren funktionieren mit QTextstream immer. Eben WEIL QIODevice als Basisklasse designt wurde.
So weit so gut.
In der C++ I/O Library gibt es Ähnliche Ansätze.
* Ich will von einer Datei lesen/schreiben, nehm ich basic_fstream.
* Ich will von einem String lesen/schreiben, nehm ich basic_stringstream.
* Ich will diese tollen Stream "<<" ">>" Operatoren, ja, sind schon dabei.
Und jetzt kommt der clou:
Egal ob man mit Dateien oder Strings arbeitet, die Stream Operatoren funktionieren immer. Eben WEIL basic_ostream und basic_istream als Basisklassen designt wurden.
Jetzt geht die c++ I/O Library weiter und macht noch die Unterscheidung, ob man nur lesen, nur schreiben, oder beides gleichzeitig will. Und wie es die Philosophie einer streng typ basierten Sprache so will, drückt man das in dem Typ einer Variable aus. Und nicht (nur) mit einer Laufzeit Variablen.
Aus diesem Grund gibt es neben basic_fstram auch basic_ifstram und basic_ofstram.
Und neben basic_stringstream auch basic_istringstram und basic_ostringstream. Und natürlich, neben basic_iostram auch basic_istram und basic_ostram. Damit sind 9 von 11 Klassen gefunden.
Schwachsinn? IMO! Damalig geiles Design um zu zeigen was in der Sprache steckt? Absolut!
Wir kommen zu den Templates.
Ahso, beinah hätte ich Fortran vergessen.
Bei Fortran gibt es write/read(fhdl/string).
Kennt ihr den Unterschied zwischen QString und QBytearray? Beides wird benutzt um "Text" darzustellen. Und QString ist sozusagen die Standardklasse bei Qt. Intern wird ein 16bit Character Type benutzt, statt dem sonst üblichen 8 bit. Das hat einfach den Grund, weil Qt Weltweit agiert. Und entsprechend auch Weltsprachen darstellen muss. Nun gibt es in der Welt viel mehr als 256 darstellbare Zeichen. Also wird ein 16bit Character genutzt.
Der C++ Erfinder hat das 1984 schon gesehen und die I/O Library entsprechend vorbereitet. Ob das die C++ Programmierer nun auch alle verstanden haben, sei mal dahin gestellt. Der Character Typ, ob 8bit oder 16bit, kann über Templates festgelegt werden. Die Anzahl der Klassen steigt also nicht, nur ihr Typ ändert sich.
So entspricht QBytearray std::string und QString entspricht std::wstring. Für alle vorgestellten std steram Klassen gibt es eine "normale "std::istraem" und eine "std::wistrem" Klasse. std::strinstream und std::wstringstream u.s.w.
Man sieht deutlich, dass die Information bei C++ im Type steckt. Ob pragmatisch oder schlecht sei dahin gestellt.
Bei Fortran gibt es write/read(fhdl/string) und hast du es mit ausländische Sprachen zu tun, hast du Pech gehabt.
Es fehlen noch std::basic_ios und std::ios_base. Bei Qt gibt es keine direkten Vergleichs Klassen, da die Implementierungsdetails versteckt sind. Aber bei C++ 1984 war das überhaupt noch kein Thema. Also, std::basic_ios ist eine Basisklasse von allen bisher vorgestellten std:: Klassen. Jede Funktion, die std::basic_ios bereit stellt, haben auch alle anderen Funktionen. Das sind hauptsächlich Funktionen für die Fehlerbehandlung oder den Status des internen Buffers.
Wie gesagt, das ist bei Qt alles weg-abstrahiert. Interne Buffer sind da irgendwo und machen ihren Job. Das ist für den Qt Anwender auch total egal. Hauptsache, man kann lesen/schreiben.
Aber C++ hat ja als Ziel, dass man alles tun kann. Also muss man auch die ganze Kontrolle haben. Und dennoch den Kompfor, dass man sich nicht selbst in den Fuß schießt. Naja.
Wenn bei Qt ein String NICHT in ein Integer konvertiert werden kann, dann passiert entweder garnichts, oder eine optionale logische Variable wird auf false gesetzt.
Bei C++ gibt es die Funktionen good() eof() fail() bad() oder Exception, um zu überprüfen ob alles geklappt hat. Bei Qt gibt es okay, oder nicht okay; zwei Möglichkeiten. Bei C++ gibt 16. Naja, fast. Wie immer ist C++ detaillierter. Wenn etwas nicht good() ist, dann ist es entweder eof() oder fail() oder bad(). Klar, oder?
Aber wenn eof(), dann ist das nicht unbedingt fail() oder bad(). Das Ende der Datei erreicht? Absolut kein Problem. Nun, zwischen fail() und bad() liegt der Unterschied, dass bad() schlechter als fail() ist. bad() impliziert fail(). Wenn bad() ist, dann geht es nicht weiter. Dann geht die Welt unter. Dann ist alles vorbei. Aber mit fail() koennen wir weiter leben. Eine Konvertierung von String nach Integer failt zwar, aber sonst ist alles okay und wir können weiter machen.
Wann genau welcher Fehler auftrifft, kann in der IObase Doku nachgelesen werden.
Nun gibt es seit C++ auch Exception. Alle Google Entwickler mögen hier jetzt bitte sterben. Exceptions bieten die Möglichkeit den Programmteil wo "alles ist gut", von dem Programmteil "Fehlerbehandlung" zu trennen. Liest man dann den Code von Oben nach Unten, liest man nur den Teil, der ausgeführt wird, wenn kein Fehler passiert. Nur das interessiert einem meistens.
Die Exceptions ignoriert man bei Qt komplett. Nun, das ist ein Weltweites Framework welches versucht es jedem recht zu machen. Es sei ihnen verziehen.
Bei C++ hat man, wie immer, die Wahl.
Kommen wir nun langsam zum Kern der Sache, warum ich mich damit beschäftige. Ich möchte einen XYZ Reader bauen, der stumpft pro Zeile drei Zahlen liest. Es sollen immer drei pro Zeile sein. Und ich möchte das mit pure C++ machen, weil Qt nicht überall installiert ist.
Das ist auch absolut kein Problem.
stream >> var1 >> var2 >> var3;
Das funktioniert bei C++ genauso wie bei Qt genauso wie bei Fortran. Nur da müsste man read() schreiben.
Aber was ist mit der Fehlerbehandlung? Wenn irgendwas schief läuft, dann will ich genau wissen, WAS und WO und WARUM es schief lief. Auf dumm herum Raten hab ich kein Bock. Lebenszeit und so.
Ja Scheiße, das funktioniert weder bei C++ noch bei Qt noch bei Fortran gut. Bei Fortran und Qt gib es zwar Statusvariabeln ob etwas schief lief, aber DAS etwas schief lief, muss man noch selbst prüfen. Bei C++ ist das DAS mit exceptions zwar automatisiert, aber es bleibt immer noch das WAS.
Und das WO, z.b. mit Zeilennummern, muss man alles noch selbst implementieren. Ich hätte gerne eine Fehlermeldung wie: "Datei xyz. Zeile: 123. String 'scheisse' kann nicht nach interger konvertiert werden". Ja dann ist alles klar. Und nicht "iostream error". Den Error kanntes dir sonst wo hin stecken.
Wir können dieses Verhalten natürlich selbst implementieren. Eine Zeile einlesen und parsen. Bei Fortran hat man gleich das Problem: Wie groß muss der Buffer sein? BUMM FAIL.
Bei Qt wird eine Kopie für den Buffer angelegt. BUMM Performance FAIL.
Bei C++ kapiert kein Aas wie er das implementieren soll. BUMM BRAINFAIL.
C++ soll performant sein. Und damit meinte ich nicht. "Lade die Webseite mit 4 Bildern und 3 Textzeilen in unter 10 Sekunde". Das ist für Gehirn entfernte Idioten. Ich meinte so etwas wie "Verarbeite eine Milliarden Buchstaben in einer Sekunde".
Und dazu gehört auch, dass Eingabe Daten nicht erst unnütz in einem extra Buffer geladen werden, sondern, dass gleich auf den Daten gearbeitet wird.
Und genau hier komme ich zur abstrakten Vorgehensweise von "Lese drei Zahlen pro Zeile ein". Ein Zeilenende ist durch ein \n gekennzeichnet. Es muss also erst ein Abschnitt gefunden werden, von wo bis zum nächsten \n gültige Daten vorliegen (unformatiertes lesen). Und dann erst kann auf diesem Abschnitt versucht werden, formatiert zu lesen. Also 3 Zahlen zu extrahieren. Diese Erkenntnis selbst, ist für viele schon Brainfuck genug.
Es sollen also folgende Fehler erkannt werden.
EOF bevor 3 Zahlen fertig gelesen wurden.
Newline char bevor 3 Zahlen fertig gelesen werden.
Konvertierungs Fehler von String nach Zahl.
So, und wie wird das Umgesetzt?
Erstmal die Version, welche eine Zeile in ein String einliest und dann parst.
Datei werden die Daten nicht gespeichert, nur eingelesen, geparst und verworfen.
Testdatei mit 772MB, 28895639 Zeilen a 3 Zahlen.
Workrechner:
real 0m44.049s
user 0m43.892s
sys 0m0.176s
17.55 MB/s
real 0m44.965s
user 0m44.760s
sys 0m0.216s
17.16 MB/s
Heimrechner:
real 2m0.688s
user 1m58.776s
sys 0m1.228s
6.38 MB/s
real 1m54.953s
user 1m54.172s
sys 0m0.628s
6.66 MB/s
Wir haben also ein Durchsatz von 17 MB/s bzw. 6 MB/s
std::ifstream ss(fileName);
if(!ss.is_open()) throw();
try {
ss.exceptions(std::ios_base::failbit);
for(size_t i=0; i < n and ss.good(); ++i) {
std::getline(ss, line);
std::istringstream ss2(line);
ss2.exceptions(std::ios_base::failbit);
ss2 >> data[0];
}
} catch(std::ios_base::failure& ex) {
...
}
Zwei Input streams zu erzeugen kommt mir wrong vor. Aber der eine liest unformatted und der andere formatted.
Aber der formated stream kann ja auf dem Buffer vom unformatted stream Arbeiten. Oder so ähnlich. Eigentlich, ist der newline character ein Zeichen fuer den formated stream. Und nun kann man std::ctype und die std::locale von std::istream so änderen, dass '\n' nicht als whitespace anerkannt wird. Damit es es möglich, Zahl für Zahl einzulesen aber bei '\n' ist schluss. Dummerweise muss man im dann von Hand noch '\n' und restliche whitespaces einlesen. Das führt wieder zu versteckte Fehler. Und die virtuellen Fehler sind eh Performance Killer. Das MUSS besser gehen.
Workrechner:
real 0m32.871s
user 0m32.600s
sys 0m0.276s
23.49 MB/s
real 0m32.776s
user 0m32.576s
sys 0m0.200s
23.55 MB/s
Heimrechner
real 1m37.050s
user 1m33.396s
sys 0m1.512s
7.95 MB/s
real 1m39.499s
user 1m31.360s
sys 0m1.524s
7.76 MB/s
Immerhin von 17 auf 23 bzw. von 6 auf 7 MB/s hoch.
So, habe mit mmap die Inhalt direkt ueber den Speicher zugreifbar gemacht. Zum convertieren nehme ich std::strtod und bals std::from_chars. Die arbeiten direkt auf dem Speicher. Kein dummen rumkopieren in irgendwelche Buffer mehr. Dann schaun wir mal:
Heimrechner
real 0m33.893s
user 0m31.112s
sys 0m0.876s
22.77 MB/s
real 0m30.617s
user 0m29.564s
sys 0m0.356s
25.21 MB/s
Nu schau sich das mal einer an. Von 7 MB/s auf 25 MB/s hoch. Faktor 4 schneller. Dann müsste mein Workrechner locker mit 60 MB/s arbeiten. Mit eingeschalteter Compiler Optimierung ist sogar noch etwas mehr drin.
Der Cluster parst bei eingeschalteter Optimierung die 772 MB in 9.6sec. Das macht stolze 80.4 MB/s!
Comments Off on C++ Guns - std Input/output library
15.03.2017
Biologie++ - PCR
DNA kann sich vermehren. Das wusste man schon lange. Wie genau das geht ist aber überhaupt nicht so leicht ersichtlich. PCR Polymerase-Kettenreaktion ist eine Methode um die Replikation, die normalerweise in einer Zelle stattfindet, unter kontrollierten Bedingungen im Labor durchzuführen. Dazu wird die original DNA, welche die zu vervielfältigen Abschnitte enthält, sowie Primer und DNA-Polymerase zusammen mit Nucleotide in einem Thermocycler gegeben und mehrmals erhitzt und wieder abgekühlt.
Der Ablauf besteht im wesentlichen aus drei Schritten.
Im ersten Schritt wird die DNA auf 96° (Schmelztemperatur) erhitzt um die Doppelstränge zu trennen. Bei niedriger Temperatur richten sich im zweiten Schritt die (komplementären) Primer an der DNA aus. Die genaue Temperatur wird durch die Länge und der GC-Gehalt der Primer festgelegt. Schließlich wird im dritten Schritt bei erhöhter Temperatur mit Hilfe der DNA-Polymerase der Strang mit komplementären Base wieder aufgefüllt.
Werden die Schritte mehrmals hintereinander ausgeführt, vervielfältigt sich die DNA Kettenreaktionsartig.
Comments Off on Biologie++ - PCR
Biologie++ - A T C G U
Die Buchstaben A T C G U stehen für die Basen Adenin, Thymin, Guanin, Cytosin und Uracil. Wobei Thymin und Uracil "sich ähnlich sehe" und das letzte nur bei RNA vorkommt.
Diese Moleküle bestehen aus Stickstoff, Sauerstoff, Wasserstoff und etwas Phosphor. Zucker und Klebstoff, die Bausteine des Lebens.
Adenin ist wie Guanin ein Purin. Wohingegen Thymin, Cytosin und Uracil ein Pyrimidin sind. Dabei ist Purin eine heterobicyclische aromatische organische Verbindung mit vier Stickstoffatomen. Wärend Pydimidin eine sechsgliedrige heterocyclische aromatische organische Verbindung mit zwei Stickstoffatomen ist. Adein und Guanin sind also fetter als die anderen ;) So kann sich ein Purin nur mit einem Pyrimidin verbinden. Es existiert also keine A-G Verbindung.
Die Summenformel von Adenin ist C5H5N5, die von Guanin C5H5N5O. Also ein Sauerstoff Atom ist mehr dran. Bei Thymin lautet die Summenformel C5H6N2O2, Cytosin C4H5N3O und Uracil C4H4N2O2.
Adenin bildet zwei Wassserstoffbrücken zu Thymin oder Uracil. Wärend Guanin drei Wasserstoffbrücken zu Cytosin bildet. Es wird also mehr Energie benötigt um eine G-C Verbindung aufzutrennen.
Thymin kann man aus Rinderhirn extrahieren. Genauso wie Radiergummis.
Über ein Phosphor am C5 Atoms des Thymins oder Uracils kann eine Verbindung zu anderen Nucelotides im DNA Strang hergestellt werden.
Guanin ist übrigends das Guano, was bei Fledermäusen hinten raus kommt.
Auch bei Cytosin und Gianin ist über das C5 Atom und Phosphor eine Verbindung zum DNA Strang möglich.
Comments Off on Biologie++ - A T C G U
14.03.2017
Diese Woche - 10 Jahre RoboBlog
Na sowas, sind schon 10 Jahre rum :D
Ich kann mich noch erinnern, als wäre es gestern gewesen, wie wir den Roboter bauten. Vor dem Blog gab es ein RoboWiki. Das gibt plötzlich flöten und seit dem 11.3.2007 haben wir den RoboBlog. Mein aller erster Post war dann am 18.3, und worum ging es? Na um Mikrocontroller.
10 Jahre voller Programmieren, Kuchen, Technik, Eisenbahn und zwischendurch Diverses ^^
Auf die nächsten 0xA Jahre!
Comments Off on Diese Woche - 10 Jahre RoboBlog
C++ Guns - Funktion return unterschiedliche lambda Funktionen
Na sicher geht das. Zur Compilezeit wie auch zur Laufzeit.
Zur Compilezeit wäre if constexpr angebracht, aber das kann mein Compiler noch nicht. Mit Templates wär das wieder overload. Also nehm ich stink normales Funktion überladen mit Tags.
struct Add_tag {};
struct Mult_tag {};
auto func1(int x, Add_tag) {
return [x](int y){ return x+y; };
}
auto func1(int x, Mult_tag) {
return [x](int y){ return x*y; };
}
int main() {
cout << func1(2, Mult_tag())(3) << "\n";
return 0;
}
Zur Laufzeit fällt mir std::function ein. Mit den üblichen Performancefressern.
enum class Operator {ADD, MULT};
std::function func1(int x, Operator op) {
switch(op) {
case Operator::ADD: return [x](int y){ return x+y; };
case Operator::MULT: return [x](int y){ return x*y; };
}
}
int main() {
Operator op = Operator::MULT;
cout << func1(2, op)(3) << "\n";
return 0;
}
Hübsch? Naaah. Braucht man? Bisher nicht.
Comments Off on C++ Guns - Funktion return unterschiedliche lambda Funktionen
12.03.2017
Biologie++ - DNA / RNA / UNA
Aus: On the repliaton of desoxyribonucleic acid (DNA) by M. Delbrück
The structure proposed by Watson and Crick consists of two polynucleotide chains wound helically around a common axis, tied together by hydrogen bounds between the purine and pyrimidine side chains.
These side chains of the two chains are aranged so that adenine is always matched with thymine and guanine with cytosine.
The sequence of bases along either chains is not subject to any restrictions, but once the sequence along on chain is given, the sequence along the other chain is completely determinded. This sequence, then, constitutes the genetic information, a linear message written in a four-symbol code. The duplex of the two chains contains the information in a twofold redundance. Each chain has a directional polarity because of the nonequivalence of the 3- and 5- positions through which each pentose is linked to the preceding and the following phosphate group in the chan. This polarity runs in opposite directions in the two chains of the duplex.
Und ein Übersetzungsversuch
The Struktor vorgeschlagen von Watson und Crick besteht aus zwei poly nukleotide Ketten welche sich spiralförmig um eine gemeinsame Achse winden. Sie sind zusammengebunden durch Wasserstoffbrücken zwischen der purine? und pyrimidine? Seitenketten.
Die Seitenketten von den beiten Ketten sind so angeordnet, dass Adenine immer passend zu Thymine und Guanine mit Cytosine angeordnet sind.
Die Sequenz von Basen von einer Kette ist keiner Beschränkung unterlegen, aber sobald die Sequnez entlang einer Kette festliegt, so ist die Sequenz der anderen Kette komplett festgelegt. Diese Sequenz stellt die genetische Information dar. Eine lineare Nachricht, geschrieben in ein vier Symbol Code.
??? zweifachen Redundance. Jede Kette hat eine Richtungspolarität weil 5- und 3- nicht equivalent sind. Die 5- und 3- Positionen durch welche jede pentose verbunden ist durch die vorangegangene und nächste Phosphategruppe in der Kette. Die beiden Ketten verlaufen in entgegengesetzen Richtungen.
Und ein wenig aus Wikipedia
Die Gene in der DNA enthalten die Information für die Herstellung der Ribonukleinsäuren (RNA, im Deutschen auch RNS). Eine wichtige Gruppe von RNA, die mRNA, enthält wiederum die Information für den Bau der Proteine (Eiweiße), welche für die biologische Entwicklung eines Lebewesens und den Stoffwechsel in der Zelle notwendig sind. Innerhalb der Protein-codierenden Gene legt die Abfolge der Basen die Abfolge der Aminosäuren des jeweiligen Proteins fest: Im genetischen Code stehen jeweils drei Basen für eine bestimmte Aminosäure.
DNA --Info--> RNA -| (message)mRNA --Info--> Proteine | (Base,Base,Base) -> Aminosäure
| (ribosomale) rRNA
| (transfer) tRNA
Es gibt noch UNA, unique nucleotide sequence. Eine Definition habe ich bei medical-dictionary gefunden:
unique DNA
DNA sequences that occur only once in the haploid genome
Ja, ein Stück DNA, dass es so nur einmal im Kochtopf gibt, damit beim Assemblieren der Gene nichts falsch verbunden wird.
Comments Off on Biologie++ - DNA / RNA / UNA
11.03.2017
C++17 Guns - std::optional Part IV
Der Übergang von cpl::optional nach std::optional ist schnell gemacht. Nur beim Zugriff ändert sich sichtlich etwas. Wir können operator*, operator->, value() oder value_or() nutzen. Das sieht alles nicht gut aus:
if(DMP and SMP) {
if(fuzzyEqual(abs(DMP->point.z - SMP.value().point.z), schacht.tiefe) == false) {
cout << "Redundante Information Schachttiefe vs DMP-SMP";
}
}
Bei operator-> denkt man gleich an Pointer. Bisher war es aber immer operator. gewesen. Und der extra Umweg über value() ist auch too verbose. Wenn wir mehr Richtung funktionaler Programmierung denken, dann ergibt sich die Möglichkeit, den ekligen Zugriff in einer Funktion zu verstecken. Diese Funktion bekommt beide Punkte, und eine Funktion, was mit den Punkten gemacht werden soll.
Das könnte in etwa so aussehen:
template
void maybeBoth(const optional& x, const optional& y, Function func) {
if(x and y) {
func(*x, *y);
}
}
maybeBoth(schacht.DMP(), schacht.SMP(),
[&schacht](const Punkt& DMP, const Punkt& SMP) {
if(fuzzyEqual(abs(DMP.point.z - SMP.point.z), schacht.tiefe) == false) {
cout << "Redundante Information Schachttiefe vs DMP-SMP";
}
}
);
Hmm mit der Einrückung hab ich so meine Probleme. Jedenfalls wäre das die kürzeste Variante, denn der maybeBoth Ausdruck ist nur eine Zeile. Der komische Zugriff ist weg, dafür müssen wir eine Funktion, oder ein Lambda definieren. Welches wiederum ein Funktionskopf mit Parameter braucht. Das ist wieder sehr verbose... In anderen Sprachen ist die Syntax angeblich viel besser.
Hm es ist anders zu lesen. Ungewohnt. Funktional eben. Da steht kein if() mehr. Das "Wenn" steckt jetz in "maybeBoth". Aber maybe was? Dass schacht.DMP() ein optional zurück gibt, ist hier nicht ersichtlich. Die logische Verknüpfung, dass DMP UND SMP existieren müssen ist hier nicht ersichtlich. Sicher, man kann das in der Dokumentation so festhalten von maybeBoth() und nach einer weile hat man das drauf.
Aber für ein winziges Stück Code, was ich maximal schnell hinschreiben will (Zeit ist Lebenszeit), ist das doch nichts. Womöglich sollte ich "maybe" durch "if" ersetzen. Also ifBoth(DMP, SMP)? Oder ifBothExist(DMP, SMP) ? Sieht schon besser aus. Voll viel Arbeit...
Aber nochmal kurz zurück an den Anfang. Was gewinne ich dadurch? Dass T in cpl::optional
Eine Sache bleibt noch aus. Was passiert, wenn ich neben DMP und SMP auch noch RAP und SA brauche? Und ich möchte nicht die Schleife in Schacht::x vier mal laufen lassen. In nur einer Schleife soll überprüft werden, ob alle geforderten Punkte existieren und auf einmal, alle als optional, zurück gegeben werden. Ob das gut funktioniert?
Comments Off on C++17 Guns - std::optional Part IV
C++17 Guns - std::optional Part III
So, kommen wir zum dritten Teil. Zu Versuchs und Lernzwecken habe ich meine eigene cpl::optional Klasse geschrieben, die genau das macht, was ich zur Zeit brauche. Ich mache mir absichtlich das Leben einfach und vordere, dass der Typ default constructible sein muss. Hält cpl::optional kein Wert, so ist ein default Wert gespeichert. Das hat die schon beschriebenen Nachteile, aber man muss ja pragmatisch denken. Die Syntax soll nicht so einfach wie möglich sein, sondern so einfach, wie sie vorher schon war. Zum Vergleich zeige ich den alten Code, eine funktionale Version und eine neue Version
Alter Code:
bool hasDMP = false;
Punkt DMP;
bool hasSMP = false;
Punkt SMP;
for(const Punkt& punkt : schacht.punkte) {
if(punkt.attr == PunktAttributAbwasser::DMP) {
hasDMP = true;
DMP = punkt;
} else if(punkt.attr == PunktAttributAbwasser::SMP) {
hasSMP = true;
SMP = punkt;
}
}
if(hasDMP and hasSMP) {
if(fuzzyCompare(abs(DMP.point.z-SMP.point.z), schacht.tiefe) == false) {
cout << "Redundante Information Schachttiefe vs DMP-SMP";
}
}
Diese Version hat folgende Nachteile und sleeping errors (Phew wo fang ich denn an).
a) WAS vs. WIE. In dem Code steht, WIE die zwei Punkte gefunden werden und danach WIE damit weiter verfahren wird. Aber es steht nicht da WAS überhaupt gemacht werden soll.
b) SMP und DMP sind ähnlich geschriebene Variablen die leicht verwechselt werden können. Das sind aber vorgegebene Abkürzungen die es einzuhalten gilt. Viel schlimmer aber sind die beiden zusätzlichen bool Variablen. Es können die bool und Punkt Variablen in jeder Kombination vertauscht werden.
c) Die Lebenszeit der DMP und SMP Variablen ist zu lange. Nach der letzten if() geht der Code normalerweise noch weiter. Hier könnte man eine der Variablen wieder benutzen, obwohl das gar nicht beabsichtigt ist. Ein ähnliches Problem hat die Sprache C mit der Laufvariable i in for() Schleifen. Das ist seit 1984 in C++ nie wieder ein Fehler gewesen.
d) RAII nicht beachtet. Erst wird der Punkt default initialisiert, und später vllt. einem anderen Punkt aus dem Schacht zugewiesen. Statt gleich die Zuweisung zu machen.
e) Und letztendlich wird eine Kopie des Punktes erzeugt. Das ist in diesem Fall aber das kleinere Übel. Referenzen, Indices, Iteratoren oder Pointer können alle invalid werden, sollte sich die Punkte in dem Schacht zwischenzeitlich ändern.
Hier sind Lösungsvorschläge:
a) Die Schleife muss in eine Funktion ausgelagert werden.
b) Punkt und bool Variable in ein neuen Datentyp koppeln.
c) Mehrere Möglichkeiten:
Scope durch zwei Klammern {} verkleinern.
Code in eine weitere Funktion packen.
C++17 "Selection statements with initializer" nutzen.
d) Auch (teil)gelöst durch Schleife in Subroutine.
Punkt a) ist trivial. Das sollte etwa so aussehen: auto DMP = punkt.DMP();
Punkt b) ist durch ein optional lösbar. Ich zeige Code mit std::optional und cpl::optional.
Punkt c) C++17 ist natürlich vorzuziehen.
Punkt d) Da cpl::optional default constructible brauchst ist hier RAII nicht so zu 100% enigehalten.
Fangen wir an:
cpl::optional<Punkt> Schacht::DMP() const {
for(const Punkt& punkt : punkte) {
if(punkt.attr == PunktAttributAbwasser::DMP) {
return punkt;
}
}
return {};
}
Im Erfolgsfall wird der Punkt zurück gegeben, sonst ein default cpl::optional, welches keine Daten hält. Für SMP() analog. Um zu testen ob ein std::optional ein Wert hält, gibt es die Funktionen has_value() oder operator bool. Ich möchte gern die Funktion beim Namen nennen, um den Code lesbarer zu halten. Aber punkt.has_value() ist.. seltsam. Jeder Punkt hat doch Werte? Daher nehme ich für cpl::optional lieber den Funktionsnamen exist(). Und so schauts aus:
auto DMP = schacht.DMP();
auto SMP = schacht.SMP();
if(DMP.exist() and SMP.exist()) {
if(fuzzyCompare(std::abs(DMP.point.z-SMP.point.z), schacht.tiefe) == false) {
cout << "Redundante Information Schachttiefe vs DMP-SMP";
}
}
Das ist schon wesentlich lesbarer. Hier empfiehlt sich die NUtzung von "auto", sonst müsste man umständlich cpl::optional
if(auto DMP = schacht.DMP(); DMP.exist()) {
if(auto SMP = schacht.SMP(); SMP.exist()) {
if(fuzzyEqual(std::abs(DMP.point.z-SMP.point.z), schacht.tiefe) == false) {
std::cout << "Redundante Information Schachttiefe vs DMP-SMP";
}
}
}
Jetzt bin ich mir nur nicht sicher, ob die Initialisierung in der if() auch für mehrere Variablen funktioniert, oder ob der Compiler noch buggy ist. Aber jedenfalls, aus den anfänglichen 19 Zeilen Code sind es 7-8 geworden. Ein WIE wurde in ein WAS verwandelt. Der zweite Teil mit dem fuzzyEqual lass ich mal so stehen.
Hier die Implementierung von cpl::optional
namespace cpl {
template<class T>
struct optional : public T {
static_assert(is_default_constructible<T>::value);
optional() = default;
optional(const T& t)
: T(t), vorhanden(true)
{
}
explicit operator bool() const {
return vorhanden;
}
bool exist() const {
return vorhanden;
}
bool vorhanden = false;
};
}
Das nächstemal geht es mit std::optional weiter
Comments Off on C++17 Guns - std::optional Part III